
Traditional Software Development data models, which appear to indicate or infer that reads and writes are in synchronization when it comes to interacting with the database, in order to maintain the ACID( Atomicity, Consistency, Isolation, Durability) properties pertaining to the data.
ACID is a standard set of properties that guarantee that database transactions are processed reliably and is primarily concerned with how a database recovers from any failure that might occur while processing a transaction. Typically, an ACID-compliant DBMS (Database Management System) ensures that the data in the database remains accurate and consistent despite any such failures.
Atomicity
Atomicity guarantees that either all of the transaction succeeds or none of it does. You don’t get part of it succeeding and part of it not. If one part of the transaction fails, the whole transaction fails. With atomicity, it’s either all or nothing.
Consistency
This ensures that you guarantee that all data will be consistent. All data will be valid according to all defined rules, including any constraints, cascades, and triggers that have been applied on the database.
Isolation
Guarantees that all transactions will occur in isolation. No transaction will be affected by any other transaction. So a transaction cannot read data from any other transaction that has not yet completed.
Durability
Durability means that, once a transaction is committed, it will remain in the system – even if there’s a system crash immediately following the transaction. Any changes from the transaction must be stored permanently. If the system tells the user that the transaction has succeeded, the transaction must have, in fact, succeeded.
The ACID properties are designed as principles of transaction-oriented database recovery.
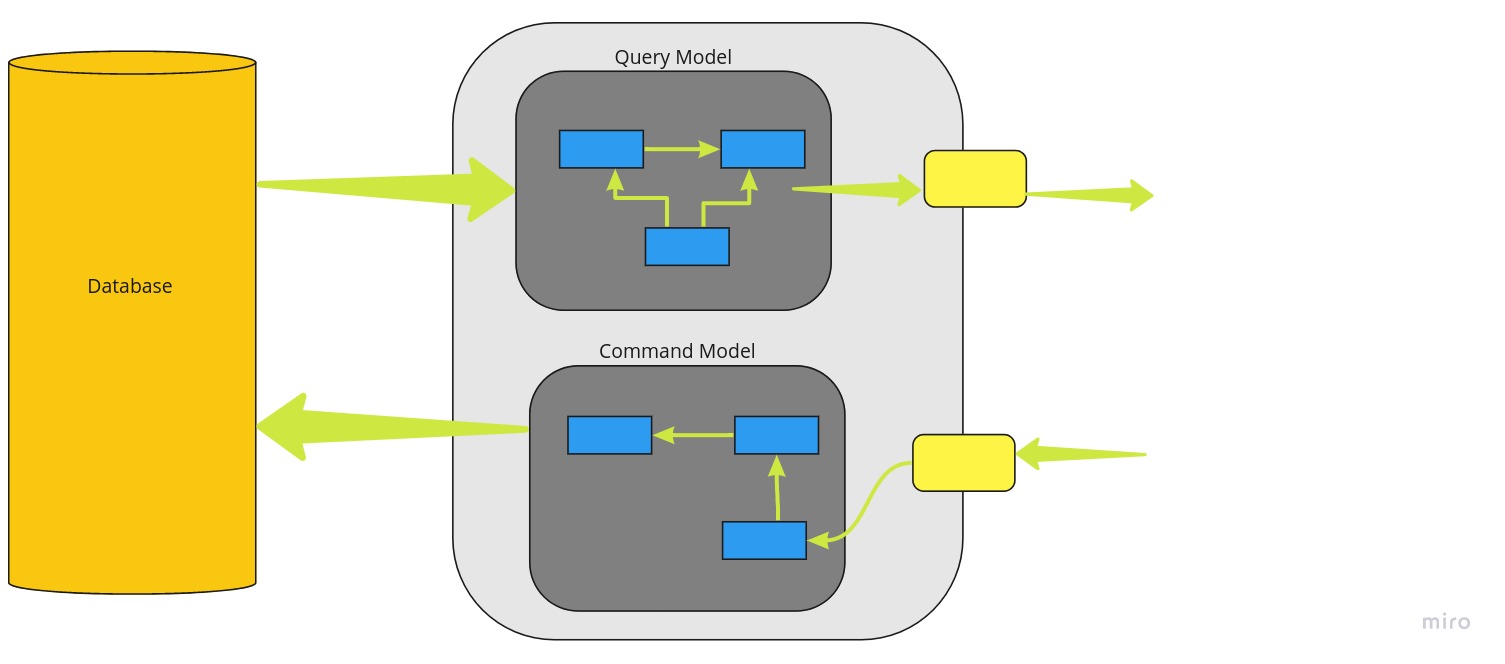
Here comes the role of CQRS which stands for “Command Query Responsibility Segregation” which specifies that different data models should be used to for updating the database and read from the database. Command and Query are two operations that stand for read and writes respectively.
Traditional operations such as CRUD – create, read, update and delete are mainstream operations carried out on databases regularly. But as our needs become more sophisticated, we turn on to new and efficient ways of working with data. By separating the command and query operations means that operations run on separate logical processes, probably on a separate hardware. A change initiated in a database routes to the command model for updating the database and then later the query model for reading from database.
Command Query Responsibility Segregation
Command Query Responsibility Segregation (CQRS) is a Software Design pattern which at a very high level defines the notion that developers use different models for Read and Update processes.
The main use of CQRS pattern using it in high-performance applications to scale read and write operations. Thus, every method should either be a Command or a Query that performs separate actions but not both simultaneously.
The conventional intuitive approach in software development when developing CRUD (Create Read Update Delete) applications, is to use the same mental model. We tend to think in terms of how everything relates to a Single model view of an object.
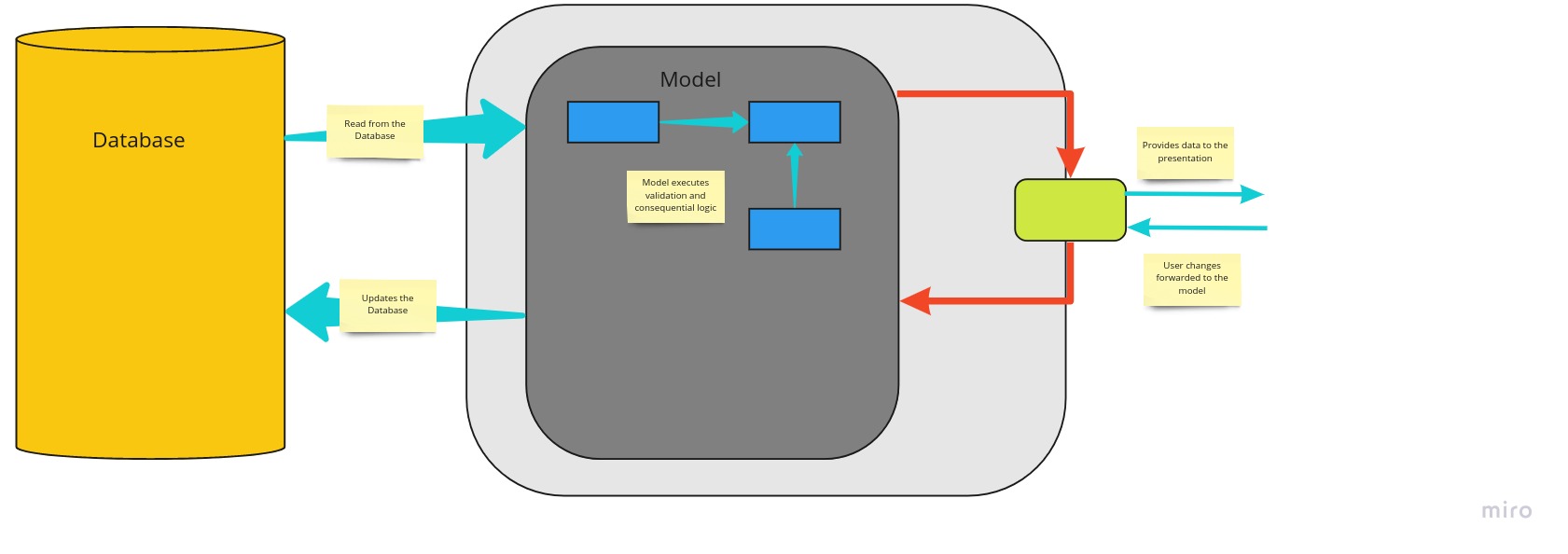
However, over time the needs and solutions become more sophisticated and we steadily change our thought processes and we start to look and need information in different ways. Usually collapsing the Model to provide scaled down representations or removing some elements of data that is not needed to satisfy a business need and in other cases we only need to update selective bit of information. We also find that there are different sets of business validation rules that need to applied at different stages of the object update process.
It is at this stage we realise that we need multiple representations of the information and also as more users interact with the information they start to require various alternative presentations of this data, with different representations.
The multi layers of representations of the data introduces a lot of complexity, which often includes a number of similarly named properties etc. The single conceptual representation acts as the main conceptual integration point, and introduces confusion. Having the same conceptual model for commands and queries leads to a more complex model that does neither well.
Using the CQRS we are able to split the conceptual models into separate models for Update and Retrieval , referring to them as Command and Query objects respectively.
Separating the models we inevitably evolve to having to different object models, which can also be executed in different logical processes and even in separate containers and hardware.
Where does CQRS fit in with other Architectural patterns
CQRS is a natural fit with the following:
- Task based UI systems
- Event-based programming models
- Event-Driven Microservices
- Eventual Consistency
- Domain Driven Design
When to use CQRS
It must be stressed that CQRS is not the golden hammer of software design patterns. Teams can get themselves into more trouble trying to implement CQRS based systems than actually solving their initial problem.
In the world of Event-Driven Microservices CQRS is a natural choice, because ultimately many of these implementations are modelled after the Domain Driven Design concepts of Bounded Contexts, which means each Bounded Context needs its own decisions on how it should be modelled.
CQRS allows you to separate the load from reads and writes allowing you to scale each independently. Which makes it an ideal choice if you are developing high performance applications.
CQRS should also be used with caution and you should remember that while CQRS is a good pattern to have in the toolbox, beware that it is difficult to use well and you can easily chop off important bits if you mishandle it.
A fairly common implementation of the CQRS pattern, is when a web based API, is split into two distinct Microservices 1 Microservice is Responsible for Read Operations and the other is responsible for Write Operations.
This may be because there is more READ operations than there are WRITE operations the services may want to use more cache etc to reduce latency. In this instance an organisation may want to break up the implementation of the API into two separate services but with access via an API Gateway such as Kong Konnect
This obviously does create a bit more overhead when it comes to separating and moving logic from a centralised domain object into multiple action objects.
The Mediator Pattern
A popular software design pattern used when implementing CQRS is the Mediator Pattern